
Simulation nutzen um Machine-Learning-Algorithmen zu trainieren
Daten zum Training und Testen von Machine-Learning-Algorithmen mit Hilfe von Simulationen generieren

Dominik Schröck
18.3.2019
Ein Überblick über die Überwachung langjähriger Simulationen und die Nutzung der Daten für Machine-Learning-Ziele
Eine der Herausforderungen beim Trainieren und Testen von ML-Algorithmen besteht darin, qualitativ hochwertige Daten zu erhalten: Die Live-Daten, mit denen Ihre Algorithmen arbeiten sollen, sind oft nicht von Anfang verfügbar, und selbst wenn sie vorhanden sind, enthalten sie möglicherweise nicht alle Merkmale, auf die Sie Ihren Algorithmus trainieren möchten.
Ein Ansatz, um damit umzugehen, ist die Erzeugung von Daten mithilfe von Simulationen - dies gibt Ihnen die volle Kontrolle sowohl über die in den Daten enthaltenen Merkmale als auch über das Volumen der Daten.
In diesem Beitrag zeigen wir Ihnen, wie Sie langlaufende Simulationen überwachen und die Daten für Machine-Learning-Zwecke nutzen können, ohne eigene Hardware zu nutzen und mit möglichst wenig Code! Dieses Beispiel nutzt Simulationsdaten, die mit unserem eigenen BPTK-Py Framework erzeugt wurden. Wir setzen verschiedene Amazon-Web- Services-Anwendungen ein, um uns auf Analytics und ML zu konzentrieren und nicht auf Code und Hardware/Software.
Die Herausforderung
Computational Essays auf Basis von Simulationsmodellen schreiben haben wir erklärt, wie Sie erfahren, wie wir eine Python-basierte Simulationsengine für System Dynamics und agentbasierte Modellierung entwickelt haben. Sie ermöglicht die Ausführung komplexer Simulationen innerhalb der Jupyter-Umgebung und den Zugriff auf die Simulationsergebnisse für weitere Analysen.
Machine-Learning-Algorithmen werden Teil unseres täglichen Lebens. Werbetreibende verbessern ihr Targeting anhand des Surfverhaltens von potenziellen Kunden. Unternehmen nutzen immer mehr Datenquellen - sowohl interne als auch externe, um zukünftige Umsätze zu prognostizieren und ihre Strategie zu ändern, alles unterstützt durch ML. Hersteller wollen Maschinenleistung und Fehler vorhersagen, um Produktionsausfälle oder gar Unfälle zu reduzieren.
Die Wahl des richtigen Machine-Learning-Algorithmus ist schwierig. Sie erfordert große Datenmengen aus der realen Welt. Aber die Verfügbarkeit solcher Daten ist nicht immer gegeben. Jemand aus der Vertriebsabteilung kann Ihnen vielleicht die Umsatzdaten des letzten Jahres geben. Aber wer hat diese Marktforschungsdaten? Können Sie Zugang zu den rohen Website-Trackingdaten bekommen? Vielleicht brauchen Sie diese Daten auf Click-Stream-Ebene. Aber das DWH speichert sie vielleicht nur aggregiert in minütlicher Auflösung oder angereichert mit anderen - für Ihr Problem nutzlosen - Informationen.
Mit BPTK können Sie Modelle entwickeln und sie schnell testen. Wie wäre es, wenn wir Simulation und Rapid-Prototyping von Machine-Learning-Algorithmen kombinieren? Auf diese Weise vermeiden Sie die nicht enden wollende Suche nach Daten aus der realen Welt. Mit unserem Ansatz können Sie:
- Realitätsnahe Daten simulieren
- Verschiedene ML-Algorithmen zur Lösung Ihres Problems testen
- Lernen, welche Datenquellen zur Lösung Ihres Problems beitragen
- Ihre Erkenntnisse vor Entscheidungsträgern präsentieren und die Vorteile des Einsatzes von ML-Methoden in Ihrem Unternehmenskontext beweisen
Im Folgenden möchten wir Ihnen an einem kleinen Beispiel zeigen, wie wir die agentenbasierte Modellierung für einige ML-Anwendungsfälle genutzt haben.
Amazon-Web-Services (AWS)
Amazon-Web-Services (AWS) ist ein leistungsstarker Service für die Bereitstellung von skalierbaren Online-Rechen- und Speicherdiensten. AWS stellt Services zur Datenanalyse bereit, was bedeutet, dass Sie Datenpipelines mit nur wenigen Klicks bereitstellen können.
Warum wir AWS in diesem Showcase verwendet haben? Weil es uns erlaubt, uns auf Machine-Learning zu konzentrieren, anstatt die Infrastruktur bereitzustell und große Mengen an Code zu schreiben, bevor wir überhaupt in der Lage sind, ML zu testen. Wir werden später in diesem Blogbeitrag näher auf die spezifischen Services eingehen, die wir verwendet haben.
Das Simulationsmodell
Wir verwenden eine Simulation eines Elektroautos. Dies ist ein klassischer IoT(Das Internet der Dinge)-Anwendungsfall. Heutzutage senden die Autos ständig Statistiken an die Server der Hersteller, um das Produkt zu verbessern. Die Daten werden in Echtzeit verarbeitet. In der Simulation agiert jedes Auto als Agent und hat eine Batterie. Wir haben weder einen Motor noch andere Komponenten modelliert, um das Modell so einfach wie möglich zu halten. Gehen wir kurz auf die Simulationsmodelle und die von uns gemessenen Variablen ein. Abbildung 1 veranschaulicht die Zustände des Autos, mit denen wir arbeiten werden.

Abbildung 1: Zustandsdiagramm für Autobatterie-Simulation
In jeder Simulationsrunde fährt oder lädt das Auto oder die Batterie wird ausgetauscht. Die Batterie kann defekt sein. Bei einem Batteriefehler dauert es einen weiteren Simulationszeitschritt, um die Batterie zu ersetzen. In diesem einfachen Modell fällt eine Batterie aus, wenn ihre Kapazität unter 14.000 A fällt, bei einer Start-Kapazität von 20.000 A. Die Kapazität verringert sich mit jeder Runde durch Fahren und Aufladen, genau wie in der realen Welt. Die Batteriezustände werden im Feld "Batterie Zustand" gespeichert. Während der Fahrt verbraucht das Auto 39,7 Ampere pro Kilometer, was zu etwa 500 km pro Vollladung führt (wenn die volle Kapazität noch verfügbar ist). Die Anzahl der in einem Simulationszeitschritt gefahrenen Kilometer ist ein Zufallswert innerhalb bestimmter Grenzen, die durch eine Fahrstrategie vorgegeben sind. Der Austausch erfolgt nur, wenn die Batterie zuvor in den ausgefallenen Zustand eingetreten ist. Immer wenn das Fahrzeug fährt, speichert das Feld "Entfernung im Zeitraum" die gefahrenen Kilometer innerhalb des gegebenen Simulationszeitraums. Beim Laden wird es standardmäßig auf Null gesetzt. Das Feld "Ladung' misst den aktuellen Ladezustand der Batterie. Das Feld "Zyklen"' erhöht sich bei einer vollen Aufladung um eins. Das Auto lädt, wenn eine untere Grenze der Ladung erreicht ist. Diese untere Grenze wird ebenfalls durch die Strategie definiert.
Die Auswahl der Strategie ist bei der Modellinitialisierung zufällig. Wir definieren drei Fahrstrategien:

In diesem Artikel konzentrieren wir uns auf die Kapazität der Batterie. Die Kapazität ermittelt, ob die Batterie ausgetauscht werden muss. Es wäre toll, diesen Wert vorhersagen zu können. Daher sollten wir einen Blick auf die Kapazität der Batterie über die Zeit für einen Agenten werfen. In Abbildung 2 sehen Sie die Ergebnisse einer Simulation, die 100.000 Schritte lang lief. Wir sehen deutlich ein recht einfaches Muster: Die Kapazität beginnt bei 20.000 Ampere und sinkt - fast linear - auf 14.000, bevor die Batterie ausgetauscht wird und das Muster erneut beginnt. Wenn Sie sich einen Zyklus genauer ansehen, werden Sie feststellen, dass die Kapazitätsabnahme nicht wirklich linear ist. Das liegt daran, dass das Auto innerhalb der Grenzen der Strategie bestimmte Kilometer fährt und nicht eine feste Anzahl von Kilometern in jedem Zeitschritt. Man könnte jedoch leicht eine Funktion konstruieren, um ein Batteriefehlerereignis abzuschätzen.
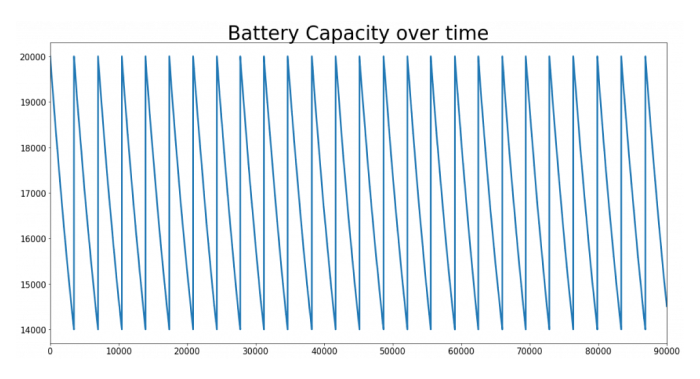
Abbildung 2: Batteriekapazität über die Zeit für die Autosimulation. Schritte: 100.000
Dieses Modell ist zwar recht einfach, aber für unsere Zwecke gut genug, um Methoden zur Prognose von Batteriefehlern zu testen. In der realen Welt ist eine Prognose-Engine für Batteriefehler nützlich, um den Fahrer über die Vereinbarung eines Termins mit der nächsten Werkstatt zu informieren - bevor er mitten auf der Straße eine Panne hat.
Um solche Probleme vorherzusagen, können Autohersteller Data Science-Techniken einsetzen. Ein Auto könnte seine eigenen Telemetriedaten an die Server des Herstellers senden, der ein trainiertes Modell auf der Grundlage von Millionen anderer Autos verwendet. Als Reaktion darauf könnte es eine Warnung erhalten, wenn ein Batteriefehler in naher Zukunft vorhergesagt wird.
Technologien, die in diesem Proof-of-Concept verwendet werden
Abbildung 3 zeigt die Struktur unseres Frameworks für maschinelles Lernen, das in diesem Proof-of-Concept verwendet wird. Während die Simulation in einer beliebigen Python-Umgebung ausgeführt werden kann, wird der Rest unserer Datenpipeline von verschiedenen Amazon Web Services-Anwendungen verarbeitet. Für umfangreiche Simulationsaufträge verwenden wir eine EC2-Instanz. Die folgenden Abschnitte gehen auf diese AWS-Pipeline und die verwendeten Technologien ein.

Abbildung 3: Datenpipeline
AWS Kinesis (Stream, Analytics, Firehose)
AWS Kinesis bietet Nachrichtenwarteschlangen- oder Datenströme. Jeder Strom kann einen oder mehrere Produzenten und Konsumenten haben. Produzenten veröffentlichen Daten, während Verbraucher sie zur weiteren Verarbeitung abrufen. Kinesis sorgt dafür, dass die Daten an alle Konsumenten verteilt werden und hält sie für eine definierte Dauer vor. Für die Berechnung einfacher aggregierter Kennzahlen haben wir Kinesis Analytics eingesetzt. Dieser Dienst greift auf Kinesis Streams zu und ermöglicht einen SQL-ähnlichen Zugriff auf die Daten. Da wir es mit Streaming-Daten zu tun haben, die nie enden, benötigt jede Abfrage ein Fenster für die Verarbeitung von Aggregaten. Fenster sind entweder Zählfenster oder Zeitfenster. Ein Zählfenster nimmt eine feste Anzahl von Datensätzen, z. B. 1.000 Datensätze, und berechnet ein Aggregat (AVG, MIN, MAX und so weiter). Ein Zeitfenster hingegen sammelt die Datensätze eines definierten Zeitintervalls. Außerdem kann ein Fenster entweder gleitend oder rollierend sein. Ein rollierendes Zählfenster von 100 berechnet die Aggregation immer dann, wenn 100 Ereignisse eingetroffen sind. Ein gleitendes Fenster der gleichen Größe löst immer dann aus, wenn ein neues Ereignis eintrifft und nimmt alle vorherigen 99 Elemente dieses bestimmten Ereignisses auf.
Wir haben die folgenden drei Abfragen implementiert, um die Fähigkeiten von Kinesis Analytics zu zeigen:
- Durchschnittlich gefahrene Kilometer pro Zeitraum in den letzten 10 Zeiträume: Zeigt die durchnittliche Fahraktivität.
- Durchschnittliche Anzahl gefahrener Kilometer, bis der Akku ausfällt: Beantwortet die Frage, wie viele Kilometer Autos zurücklegen, bevor die Batterie ausfällt. Diese Analyse ermöglicht uns die Bewertung der Qualität der Akkus. Je mehr Kilometer, desto besser!
- Anomalie-Erkennung: Erkennung von Anomalien in den Streaming-Daten und messen Sie diese anhand einer Anomalie-Punktzahl.
Die Ausgabe von AWS-Kinesis-Analytics-Abfragen fließt in einen anderen Kinesis-Stream. Diese Daten werden von AWS Kinesis Firehose konsumiert. Firehose nimmt einen Kinesis Stream als Input und gibt sie strukturiert an andere AWS-Anwendungen aus. Die Verwendung von Firehose vermeidet die Programmierung eines eigenen Stream-Konsumenten. Es schreibt die Streaming-Daten in die Zielanwendungen, ohne dass viel Konfiguration erforderlich ist. Hier wird Firehose zur Ausgabe der Daten an S3 verwendet, einem skalierbaren Datenspeicher - mehr dazu in einem späteren Abschnitt.
AWS Lambda
Für Prognosen verwenden wir AWS Lambda. Lambda ist ein Service, der die Ausführung von beliebigem Code - genannt Funktion - ermöglicht, wenn ein Auslöser ausgeführt wird. Eine Funktion ist zustandslos, was bedeutet, dass alle Variablen nach Beendigung der Ausführung verloren gehen. Der Code wird immer dann ausgelöst, wenn eine Bedingung zutrifft. In diesem Proof-of-Concept verwenden wir den Kinesis-Stream als Trigger. Wir haben Lambda so konfiguriert, dass unsere Funktion immer dann ausgeführt wird, wenn 100 Ereignisse eingetroffen sind.
Die Funktion selbst ist ein kleines Python-Skript, das die Datensätze empfängt, Prognosen für jeden Agenten berechnet und die Daten in einen neuen Kinesis-Stream schreibt. Die virtuelle Umgebung, in der der Code läuft, wird nur mit den grundlegendsten Python-Paketen geliefert. Daher müssen Sie die Linux-Pakete für alle Anforderungen herunterladen und dem Code-Paket hinzufügen. Beachten Sie, dass einige Pakete wie numpy und pandas kompiliert werden müssen. Wir haben eine Amazon-Linux-VM verwendet und die folgenden Befehle in einer virtuellen Umgebung ausgeführt:

Kopieren Sie einfach den Inhalt der Site-Pakete der virtuellen Umgebung in eine Zip-Datei zusammen mit Ihrer function.py. Als Nächstes haben wir die Zip-Datei in einen S3-Bucket kopiert (S3 ist ein von AWS bereitgestellter Speicherdienst) und die Lambda-Funktion so konfiguriert, dass sie die Datei vom S3-Bucket abruft.
Für die Prognose der Batteriekapazität verwenden wir autoregressive Modellierung. Diese Methode berechnet eine Funktion, die den Einfluss früherer Beobachtungen auf zukünftige Werte gewichtet. Eine Alternative ist die Verwendung eines gleitenden Durchschnitts. Beide Methoden werden häufig für Prognosen verwendet. Erweiterungen wie ARIMA (eine Kombination beider Methoden) sind ebenfalls üblich. Für das Training der Modelle verwenden wir das Python-Paket statsmodels, ein einfach zu verwendendes Paket für statistische Modellierung. Der grundlegende Trainings- und Vorhersagecode ist ziemlich einfach und geradlinig. Ein tolles Beispiel finden Sie in diesem Blogpost.
Der größte Teil des Codes befasst sich mit der Dekodierung der eingehenden Streaming-Daten und der Vorbereitung für das Modelltraining. Die Datenstruktur ist sehr intuitiv. Die Lambda-Funktion empfängt ein Dictionary mit einer Liste namens records. Jedes Listenelement speichert ein Dictionary namens kinesis, das Metadaten für den jeweiligen Datensatz sowie die Rohdaten enthält. Beachten Sie, dass die Daten aus einem Kinesis-Stream base64-kodiert in der Lambda-Funktion ankommen. Die Funktion extrahiert das Kapazitätsfeld für jeden Datensatz und schreibt sie in eine Liste. Die Modellanpassung selbst erfordert nur wenige Befehle:

AWS S3
AWS Simple Storage Service oder allgemein als "S3" bezeichnet, ist ein skalierbarer Online-Objektspeicher. Er ermöglicht es Ihnen, beliebige Daten zu speichern, die andere Anwendungen benötigen. Die Daten werden in Buckets organisiert. Jeder Bucket kann separat konfiguriert werden, einschließlich Zugriffsrechten, Sichtbarkeit und Lese-/Schreibberechtigungen. Jeder unserer Firehose-Prozesse (einer für jede Abfrage) schreibt die Ergebnisdaten in einen anderen S3-Bucket. S3 begrenzt nicht den Speicher, den Sie nutzen können. Vielmehr zahlen Sie für das, was Sie nutzen und wie viel Sie es nutzen. Das macht S3 skalierbar. Außerdem bietet es eine hohe Verfügbarkeit und Leistung. Genau wie bei allen anderen Diensten sorgt Amazon für die Bereitstellung von Hardware und Software, die für die Nutzung der Ressourcen erforderlich sind, ohne dass Sie eigene physische Hardware benötigen. Bibliotheken für S3 sind für viele Programmiersprachen verfügbar. So können auch Nicht-AWS-Anwendungen auf die Daten von S3 zugreifen.
AWS-Quicksight
Das letzte Tool in unserer Kette ist AWS-Quicksight. Quicksight ist ein Business-Intelligence-Tool, das in der Lage ist, sich mit vielen Datenquellen für grafische Analysen zu verbinden. Das Frontend ist sehr intuitiv und einfach. Um Daten aus S3 zu ziehen, klicken Sie einfach auf "Add Data Source" und wählen Sie "S3". Quicksight benötigt eine JSON-Datei, die den/die S3-Bucket(s) und Unterordner angibt, aus denen es die Daten ziehen soll. Sehen wir uns ein Beispiel an:

Das Feld URIPrefixes legt das/die Verzeichnis(e) fest, in denen nach Daten gesucht werden soll. Quicksight verarbeitet alle Einträge und zieht alle Unterordner und Dateien. Im angegebenen Beispiel werden alle Dateien und Unterordner innerhalb von s3://the-bucket/subfolder/ geparst. Das Feld globalUploadSettings enthält Informationen zu den Daten. Wir weisen Quicksight an, die gefundenen Daten als JSON-Dateien zu verarbeiten. Nachdem wir alle Datenquellen hinzugefügt haben, können wir Diagramme erstellen und die Ergebnisse analysieren.
Visualisierung und Analyse
Abbildung 4 zeigt die durchschnittliche Anzahl der Kilometer, die jeder Agent pro Zeitraum gefahren ist. Hier haben wir die Simulation für vier Agenten durchgeführt. Wir können leicht zwei Gruppen von Agenten mit unterschiedlichem Fahrverhalten identifizieren. Die Agenten mit den aggressiveren Fahrstrategien fahren auch mehr, während die konservativen Agenten - natürlich - weniger fahren. In einer Simulation mit vielen Agenten können Sie die Seriendaten als Input für das Training verschiedener Clustering- oder Klassifikationsalgorithmen verwenden.

Abbildung 4: Durchschnittliche Kilometer pro Agent pro Zeitraum
Als nächstes folgt der Anomalie-Puntkzahl - eine eingebaute Funktion, die sog. Random Forests verwendet, um Anomalien innerhalb des empfangenen Datenstroms zu erkennen. Sie sehen das Anomalie-Diagramm in Abbildung 5 für die ersten 50 Simulationszeitschritte. Das Balkendiagramm auf der linken Y-Achse stellt die Batterieladung in Ampere pro Zeitschritt dar. Das Liniendiagramm zeigt die Anomalie-Punktzahl für jeden Zeitschritt. Die Anomalie wird über alle numerischen Felder berechnet, die der Stream empfängt. Der Wert bewegt sich um 1, was sehr klein ist. Dies ist nicht unerwartet, da die Funktion keine großen Anomalien zeigt. Wir beobachten ein sehr klares Muster in der Ladekurve. Er ist niedrig, bis der Agent die Batterie wieder auflädt. Bei jedem Aufladen beobachten wir eine kleine Spitze in der Anomalie-Punktzahl. Eine Anomalie-Punktzahl wird über ein Fenster berechnet, das Sie in der Abfrage anpassen können. Sie können verschiedene Fenstergrößen verwenden, um die Anomalieerkennung zu verbessern. Ein zu großes Fenster kann zu einer sehr langsamen Reaktion auf Anomalien führen, während ein zu kleines Fenster zu vielen falsch-positiven Ergebnissen führen kann, da frühere Beobachtungen mit ähnlichen Mustern nicht berücksichtigt werden.
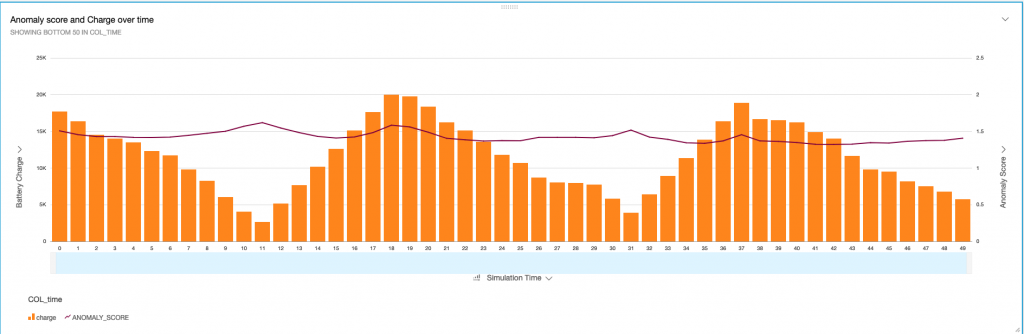
Abbildung 5: Anomalie-Punktzahl
Werfen wir nun einen Blick auf die interessanteste Grafik, die Prognose der Batteriekapazität, die in Abbildung 6 zu sehen ist. Wir sehen, wie die Prognose dem Muster der tatsächlichen Kapazitätsentwicklung ähnelt. Offensichtlich ist die AR Methode eine gute Methode für diesen Zyklus. Der Algorithmus verwendet immer die letzten 100 Beobachtungen, um die nächsten 100 Schritte zu prognostizieren. Die Prognose war in der Lage, den Trend erfolgreich vorherzusagen, und wir könnten dies als Warnung für einen Batteriefehler verwenden. Die Zahlen werden nicht zu 100% genau sein, aber eine Prognose muss nicht unbedingt die exakte Zahl treffen, sondern den Trend nachbilden, um Maßnahmen zur Vermeidung eines Batteriefehlers zu ermöglichen.
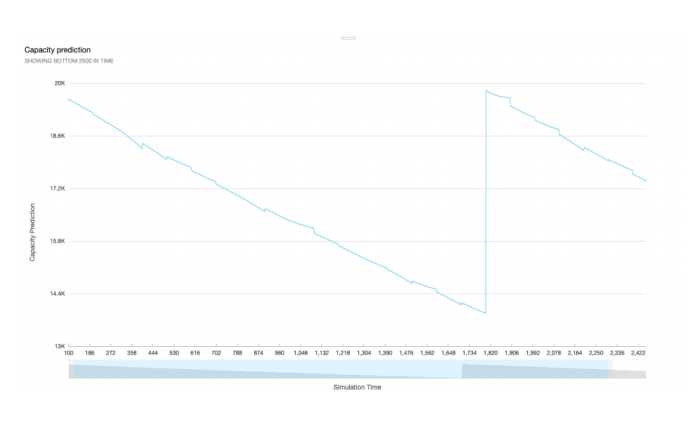
Abbildung 6: Prognose mit einem autoregressiven Modell, berechnet mit AWS Lambda
Erkenntnisse
Das Ziel dieses Proof-of-Concept war die Entwicklung einer skalierbaren Data-Intelligence-Anwendung, die Simulationsdaten verwendet. Dieser Ansatz unterstützt Machine-Learning-Projekte in einem frühen Stadium, in dem Daten aus der realen Welt knapp oder schwer zu bekommen sind. Durch den Einsatz von Cloud-Infrastruktur lassen sich komplexe Machine Learning Anwendungen einfach bereitstellen. Außerdem haben wir gezeigt, dass die Verwendung von Simulationsdaten für das Machine-Learning-Prototyping nützlich ist.
Als Data Scientist könnte ich nun andere Prognosemethoden wie Moving-Average, ARIMA oder sogar Deep-Learning mit denselben Daten testen, die wir gerade in der Simulation erzeugt haben. Und die Ergebnisse mittels Quicksight vergleichen.
Wir glauben, dass die Simulation in den frühen Phasen von Machine-Learning-Data-Science-Projekten die Entscheidungsfindung in Bezug auf die Wahl der Datenquellen, KI-Methoden und Budgetierung unterstützen kann.
Inhaltsverzeichnis
Newsletter
Bleiben sie über Inhalte und Events auf dem Laufenden.
Anstehende EventsEvents-Übersicht
Anstehende Events



Events-Übersicht


Workshops
Ressourcen
All Rights Reserved.